序列化器与请求响应
序列化器的作用
序列化: 把python中的对象转成JSON格式字符串
反序列化: 把JSON格式字符串转成python中的对象
注意: drf的序列化组件(序列化器)
把对象(Book,queryset对象)转成字典,因为有字典,直接使用Response就可以了
序列化器的使用
1. 写一个序列化类,继承Serializer
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 这里写要序列化的字段 类似于models中的字段
name = serializers.CharField()
publish = serializers.CharField()
price = serializers.IntegerField()
2. 在是视图类中使用
book_list = models.Books.objects.all()
book_ser = BookSerializer(instance=book_list, many=True)
3. 得到序列化后的数据,然后返回
return Response(book_ser.data)
'''
要写5个接口
1 获取所有 http://127.0.0.1:8000/books_new/ get
3 新增一个 http://127.0.0.1:8000/books_new/ post
2 获取单个 http://127.0.0.1:8000/books_new/1/ get
4 修改一个 http://127.0.0.1:8000/books_new/1/ put
5 删除
'''
# 可以多写类 根据ID获取值
class BookViewId(APIview):
def get(self, request, id):
book = models.Book.object.all().filter(pk=id).first()
book_ser = BookSerializer(instance=book)
return Response(book_ser.data)
# urls
path('books/<int:id>/', views.BookViewId.as_view()),
source
1. 指定要序列化表中的哪个字段
pub = serializers.CharField(source='publish')
# 将表中的 publish 取出给 pub
# source 后的字段与前面的字段不要重复
2. 还可以跨表查出
publish = serializers.CharField(source='publish.city')
SerializerMethodField
'''
要求返回的字段内是字典
publish = {'name': 名字, 'city':城市, 'email': 邮箱}
'''
# serializer.py
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.SerializerMethodField()
def get_publish(self, obj):
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
'''
[
{
"name": "三国演义",
"price": 35,
"publish": {
"name": "北方出版社",
"city": "北京",
"email": "[email protected]"
}
}
'''
# 返回的结果中又有多组数据的话使用如下方法
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
return [{'id': author.nid, 'name': author.name, 'age': author.age} for author in obj.authors.all()]
'''
[
{
"name": "水浒传",
"price": 45,
"publish": {
"name": "南方出版社",
"city": "南京",
"email": "[email protected]"
},
"authors": [
{
"id": 1,
"name": "xxx",
"age": 18
},
{
"id": 2,
"name": "yyy",
"age": 20
}
]
}
]
'''
在模型表中写方法
# 表模型中的写法
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
publish = models.ForeignKey(to='Publish', to_field='nid', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
def publish_name(self):
return {'name': self.publish.name, 'city': self.publish.city} # 返回的是一个字典
@property
def author_list(self):
return [{'id': author.nid,'name': author.name, 'age': author.age} for author in self.authors.all()]
# 序列化类中的写法
publish_name = serializers.DictField() # 接收的是一个字典 需要使用 DictField() 返回出去
author_list = serializers.ListField() # 接收的是一个列表 需要使用 ListField() 返回出去
序列化类常用字段和属性
常用字段属性
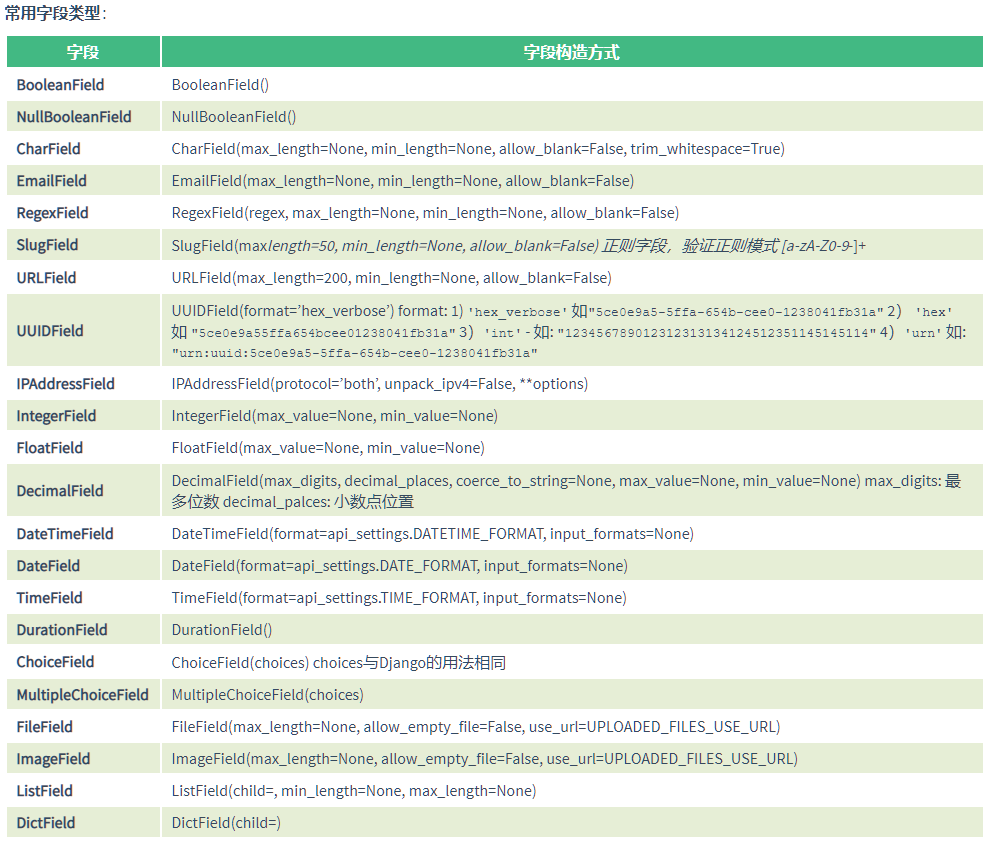
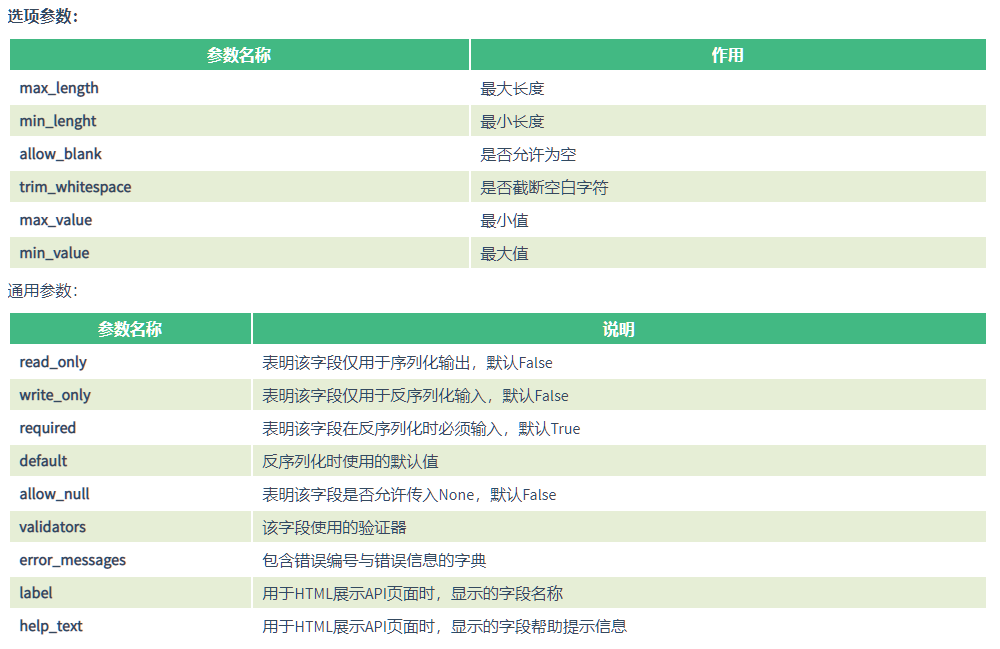
属性分类
# 针对CharField
max_length 最大长度
min_length 最小长度
allow_blank 是否允许为空
# 针对InterField
max_value 最大值
min_value 最小值
# 通用
read_only 表明该字段仅用于序列化输出,默认False(序列化)
write_only 表明该字段仅用于反序列化输入,默认False(反序列化)
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
error_messages 包含错误编号与错误信息的字典
validators 该字段使用的验证器(了解)
# 序列化类
class PublishSerializer(serializers.Serializer):
nid = serializers.CharField(required=False)
# error_messages 和forms组件中使用类似
name = serializers.CharField(max_length=3, error_messages={'max_length': '名字太长了'})
city = serializers.CharField()
email = serializers.EmailField()
# 视图类
def post(self, request):
publish_ser = serializer.PublishSerializer(data=request.data)
if publish_ser.is_valid():
publish_ser.save()
return Response(publish_ser.data)
else:
print(publish_ser.errors)
return Response(publish_ser.errors) # 此时报错信息就是 '名字太长了'
反序列化
如果要反序列化,继承了Serializer,必须重写create、updated等方法
"""
父类的save内部调用了create,所以我们重写create
return res 给了self.instance以后,instance就有值了
publish_ser.data,instance就有值调用data就能拿到序列化后的数据
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,
REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
"""
视图类
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from app01 import serializer
from app01 import models
class PublishView(APIView):
def get(self, request):
publish_list = models.Publish.objects.all()
publish_ser = serializer.PublishSerializer(instance=publish_list, many=True)
return Response(publish_ser.data)
def post(self, request):
publish_ser = serializer.PublishSerializer(data=request.data)
if publish_ser.is_valid():
publish_ser.save()
return Response(publish_ser.data)
else:
print(publish_ser.errors)
return Response('数据存在问题')
class PublishDetailView(APIView):
def get(self, request, id):
publish_list = models.Publish.objects.filter(pk=id).first()
publish_ser = serializer.PublishSerializer(instance=publish_list)
return Response(publish_ser.data)
def put(self, request, id):
publish_list = models.Publish.objects.filter(pk=id).first()
publish_ser = serializer.PublishSerializer(instance=publish_list, data=request.data)
if publish_ser.is_valid(): # 校验数据
publish_ser.save() # 保存数据
return Response(publish_ser.data)
else:
return Response('数据校验错误')
def delete(self, request, id):
res = models.Publish.objects.filter(pk=id).delete()
if res[0] > 0:
return Response('')
else:
return Response('数据不存在')
序列化类
from rest_framework import serializers
from app01 import models
class PublishSerializer(serializers.Serializer):
nid = serializers.CharField(required=False)
name = serializers.CharField()
city = serializers.CharField()
email = serializers.EmailField()
# 重写父类的 create 方法
def create(self, validated_data):
res = models.Publish.objects.create(**validated_data)
return res
# 重写父类的 update 方法
def update(self, instance, validated_data):
# 手动将值取出,再存入表中
name = validated_data.get('name')
city = validated_data.get('city')
email = validated_data.get('email')
instance.name = name
instance.city = city
instance.email = email
instance.save()
return instance # 需要将 instance 返回
表模型
from django.db import models
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
路由
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('publish/', views.PublishView.as_view()),
path('publish/<int:id>/', views.PublishDetailView.as_view()),
]
局部、全局钩子
# 序列化类
from rest_framework import serializers
from app01 import models
from rest_framework.exceptions import ValidationError
class PublishSerializer(serializers.Serializer):
nid = serializers.CharField(required=False)
name = serializers.CharField()
city = serializers.CharField()
email = serializers.EmailField()
# 局部钩子
def validate_name(self, data):
# data 就是当前字段的值
if data.startswith('sb'):
raise ValidationError('不能以sb开头') # 抛出异常 publish_ser.errors
else:
return data
# 全局钩子
def validate(self, attrs):
if attrs.get('name') == attrs.get('city'):
raise ValidationError('名称和城市名不能一致')
else:
return attrs
模型类序列化器
视图类
from rest_framework.views import APIView
from rest_framework.response import Response
from app01 import serializer
from app01 import models
class BookView(APIView):
def get(self, request):
qs = models.Book.objects.all()
ser = serializer.BookModelSerializer(instance=qs, many=True)
return Response(ser.data)
def post(self, request):
ser = serializer.BookModelSerializer(data=request.data)
if ser.is_valid():
# ModelSerializer 重写了save 方法 不用手动
ser.save()
return Response(ser.data)
else:
return Response(ser.errors)
class BookDetailView(APIView):
def get(self, request, id):
book = models.Book.objects.filter(pk=id).first()
ser = serializer.BookModelSerializer(instance=book)
return Response(ser.data)
def put(self, request, id):
book = models.Book.objects.filter(pk=id).first()
ser = serializer.BookModelSerializer(instance=book, data=request.data)
if ser.is_valid():
ser.save()
return Response(ser.data)
else:
return Response(ser.errors)
def delete(self, request, id):
res = models.Book.objects.filter(pk=id).delete()
if res[0] > 0:
return Response('')
else:
return Response('数据不存在')
序列化类
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = '__all__' # 全部字段
# fields = ['name', 'price'] # 指定字段
# exclude = ['name'] # 排除字段
# depth = 2 # 跨几个表的详细数据,一般不用,官方建议最多到10, 一般不超过3
# 某个字段用的字段类,取决于models中的字段类
# 在某个字段上加属性
extra_kwargs = {
'name': {'max_length': 6, 'required': True},
'price': {'min_value': 0, 'required': True},
'publish': {'required': True, 'write_only': True},
'authors': {'required': True, 'write_only': True}
}
# publish和authors两个字段只需要在写入时写入,而在请求时不会返回
# 而是由下面的publish_detail authors_list字段显示
# 把publish详情显示
# 重写publish字段
# publish = serializers.CharField()
# 可以加一个不存在的字段
# aa = serializers.CharField(source='name')
# 之前的方法也可以使用
# 子序列化类
publish_detail = PublishSerializer(source='publish', read_only=True)
authors_list = serializers.ListField(read_only=True)
# 这两个read_only只会在get的时候显示 写入时不需要传入
# 局部钩子、 全局钩子
表模型
from django.db import models
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
publish = models.ForeignKey(to='Publish', to_field='nid', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
def __str__(self):
return self.name
def publish_list(self):
return {'name': self.publish.name, 'city': self.publish.city}
@property
def authors_list(self):
return [{'id': author.nid, 'name': author.name, 'age': author.age} for author in self.authors.all()]
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDatail', to_field='nid', unique=True, on_delete=models.CASCADE)
def __str__(self):
return self.name
class AuthorDatail(models.Model):
nid = models.AutoField(primary_key=True)
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64)
def __str__(self):
return self.addr
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
路由
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('publish/', views.PublishView.as_view()),
path('books/', views.BookView.as_view()),
path('publish/<int:id>/', views.PublishDetailView.as_view()),
]
下图就是read_only和write_only的作用,写入的和显示的可以不一致
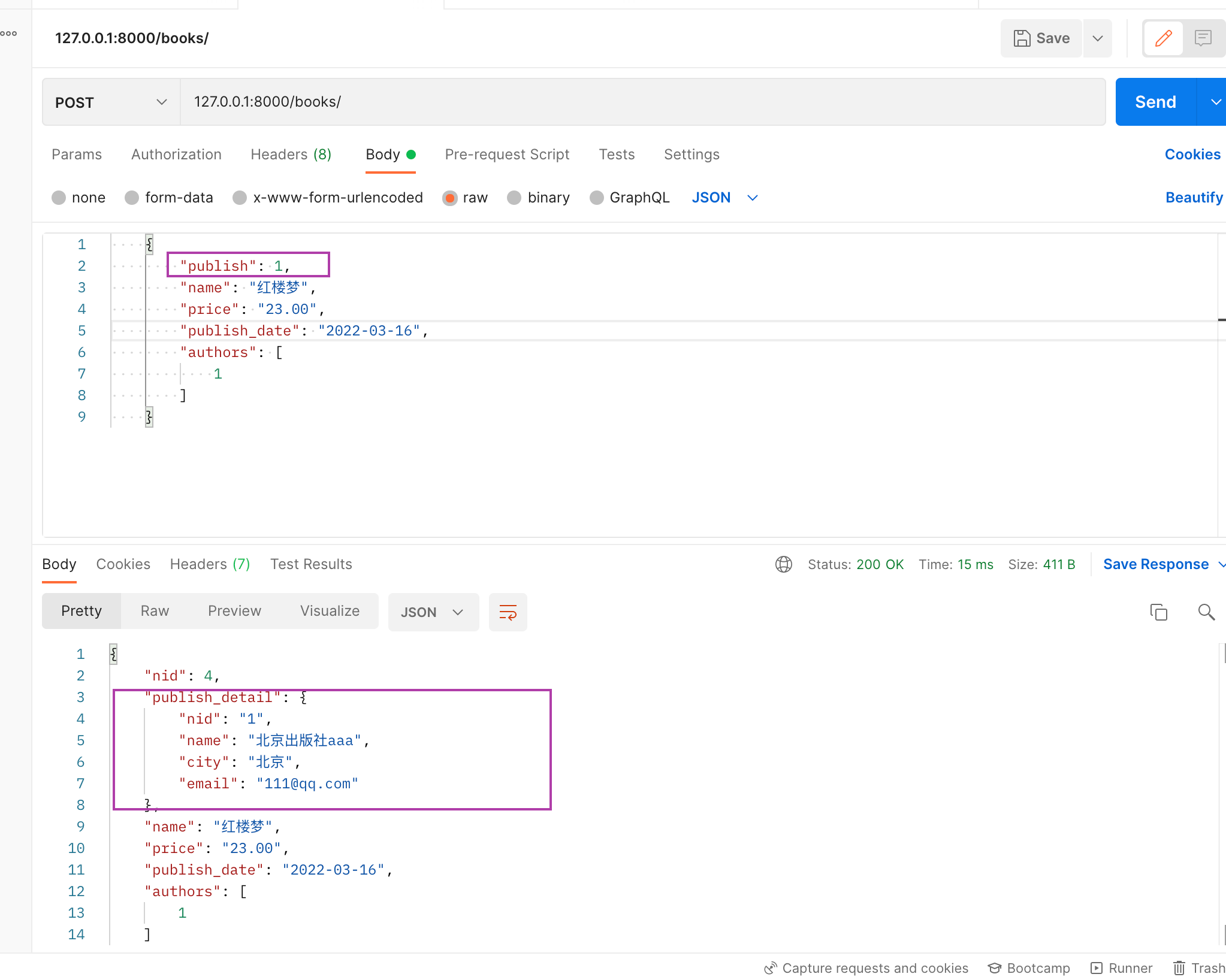
序列化源码分析
many参数
1 序列化类实例化的时候,传了many,序列化多条,不传,就序列化单条
# many=True,实例化得到的对象是ListSerializer
ser=serializer.BookModelSerializer(instance=qs,many=True)
print(type(ser))
# rest_framework.serializers.ListSerializer
# 列表中套了很多BookModelSerializer
# many=False,实例化得到的对象是BookModelSerializer
ser=serializer.BookModelSerializer(instance=book)
print(type(ser))
# app01.serializer.BookModelSerializer
类实例化:在执行__init__之前,先执行了__new__生成一个空对象(决定了是哪个类的对象)
在__new__中进行判断,如果many=True,就返回ListSerializer的对象
局部钩子和全局钩子
is_valid()
判断_validated_data如果没有
执行了 self.run_validation(self.initial_data)
目前在BaseSerializer,如果按住ctrl点击,会直接进到它父类的run_validation,进到Field,不是真正执行的方法
我们需要从头找,实际上是Serializer类的run_validation
def run_validation(self, data=empty):
value = self.to_internal_value(data) # 字段自己的校验和局部钩子
try:
self.run_validators(value)
value = self.validate(value) # 全局钩子
assert value is not None,
except (ValidationError, DjangoValidationError) as exc:
raise ValidationError(detail=as_serializer_error(exc))
return value
局部钩子是在 to_internal_value执行的
def to_internal_value(self, data):
for field in fields:
validate_method = getattr(self, 'validate_' + field.field_name, None)
if validate_method is not None:
validated_value = validate_method(validated_value)
## 总结:
is_valid---》BaseSerializer的is_valid--》执行了self.run_validation(self.initial_data)---》Serializer的run_validation---》self.to_internal_value(data):局部钩子|||
value = self.validate(value) :全局钩子
self.to_internal_value(data):局部钩子----》getattr(self, 'validate_' + field.field_name, None)
序列化对象.data
序列化对象.data方法--调用父类data方法---调用对象自己的to_representation(自定义的序列化类无此方法,去父类找)
Serializer类里有to_representation方法,for循环执行attribute = field.get_attribute(instance)
再去Field类里去找get_attribute方法,self.source_attrs就是被切分的source,然后执行get_attribute方法,source_attrs
当参数传过去,判断是方法就加括号执行,是属性就把值取出来
请求与响应
请求
# Request 类的对象---》新的request对象
from rest_framework.request import Request
# 记住的
__getattr__
request.data
request.query_parmas--->self._request.GET-->restful规范里,请求地址中带过滤(查询)条件---> get请求地址中提交的数据在GET中 --> query_parmas:查询参数
# 了解--->默认情况下,可以解析 urlencoded,formdata,json
-如果我们写了一个接口,想只能处理json格式,或者只能处理formdata
# from rest_framework import settings DRF内的所有配置的位置
# 局部配置
from rest_framework.parsers import JSONParser,FormParser,MultiPartParser
class PublishView(APIView):
# 局部使用,只针对当前视图类有效,只想处理json格式
parser_classes = [JSONParser]
# 全局配置---> 配置文件---> 所有接口都只能解析json格式
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES': [
# 解析json格式数据({"user": "zhubao"}),解析成功后,request.data类型为dict
'rest_framework.parsers.JSONParser',
# 解析form表单格式数据(user=zhubao),解析成功后,request.data类型为QuerySet
'rest_framework.parsers.FormParser',
# (用的较少),解析较为复杂的form表单格式数据,解析成功后,request.data类型为QuerySet
'rest_framework.parsers.MultiPartParser'
]
}
# 全局配置解析json,局部某个视图函数想能解析formdata格式
视图类中配置一下即可--->局部配置
如果局部配置如下:
parser_classes = [] # 所有格式都补不能解析了
# 使用顺序:我们没有配置,也有默认配置:3个都能解析
drf有默认配置(最后) ----> 项目配置文件的配置(其次) ----> 视图类中配的(优先用)
drf的默认配置:from rest_framework import settings
# 总结:一般情况下,都使用默认即可,不用配置
响应
Respone:from rest_framework.response import Response
# 属性
data=None, # 字符串,字典,列表--》给http响应body体中内容-->response对象中取出处理
status=None, # 响应状态码:1xx,2xx,3xx,默认是200
from rest_framework.status import HTTP_201_CREATED
Response(ser.data,status=HTTP_201_CREATED)
headers=None, # 响应头 字典
---了解---
template_name=None, # 模板名字(不用),用浏览器访问时,可以改
exception=False, # 异常处理
content_type=None # 响应编码格式
# 响应格式---> 跟解析格式
# 局部设置
from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
class BookDetailView(APIView):
renderer_classes = [JSONRenderer,]
# 全局设置
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': ( # 默认响应渲染类
'rest_framework.renderers.JSONRenderer', # json渲染器
'rest_framework.renderers.BrowsableAPIRenderer', # 浏览API渲染器
)
}
自定义 Response 对象
# 在app目录下手动创建response.py文件,名字随意
# 自定义一个APIResponse类,继承drf的Response
from rest_framework.response import Response
class APIResponse(Response):
def __init__(self, code=100, msg=None, data=None, status=None,
template_name=None, headers=None,
exception=False, content_type=None, **kwargs):
dic = {'status': code, 'msg': msg}
if data: # 如果data有值,说明要往里面放东西
dic['data'] = data
if kwargs: # 自定义传的参数会添加到字典里
dic.update(kwargs)
super().__init__(data=dic, status=status,
template_name=template_name, headers=headers,
exception=exception, content_type=content_type)
### 使用,在视图类中from app01.response import APIResponse # 先导入自定义的类
return APIResponse(msg='成功了',data={'name': 'lqz', 'age': 19},next=9)