Elasticsearch介绍
产生背景
大规模数据的检索
应对如下问题
大量数据存储,只要机器硬盘够,就能存储
数据安全性,分片和副本保证几个节点挂了,数据也是完整的
大数据量的检索,倒排索引
单点故障问题,分片和副本,某个节点挂了,数据完整
介绍
ES是elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据
Elasticsearch使用Java开发,在Apache许可条款下开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
设计用途:用于分布式全文检索,通过HTTP使用JSON进行数据索引,速度快
Lucene
java中的搜索引擎,但是只能给java用,比较复杂,需要懂搜索引擎的知识
python想做搜索引擎-基于lucene,进行封装,做成web服务,提供restful接口,现在无论任何语言,只要发送http的resful请求,携带参数,就能完成搜素
Lucene与Elasticsearch关系
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
和solr对比
1)Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。
2)Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr是最流行的企业级搜索引擎,Solr4 还增加了NoSQL支持。
3)Solr是用Java编写、运行在Servlet容器(如 Apache Tomcat 或Jetty)的一个独立的全文搜索服务器。 Solr采用了 Lucene Java 搜索库为核心的全文索引和搜索,并具有类似REST的HTTP/XML和JSON的API
4)Solr强大的外部配置功能使得无需进行Java编码,便可对 其进行调整以适应多种类型的应用程序。Solr有一个插件架构,以支持更多的高级定制
# solr 也是一个用java开发的企业级搜索引擎
# 传统企业喜欢用solr,互联网企业喜欢用es
# Elasticsearch 与 Solr 的比较总结
二者安装都很简单
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elastics
架构
Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群
Node:节点
形成集群的每个服务器称为节点
Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的
Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
# 注意区分主从
全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”今日是周日我们出去玩” 可能会被分词成:“今天“,”周日“,“我们“,”出去玩“ 等token,这样当你搜索“周日” 或者 “出去玩” 都会把这句搜出来
和关系型数据库的比较
mysql es
数据库 索引
表 类型
建表语句 mapping(映射)建表
数据行 文档
字段 字段
增删查改 get,put,post,delete。。。。
使用场景
# ELK---》不懂开发的运维---》不能扩展功能
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作
# ELK是Logstash、Elasticsearch、Kibana的集合。其中 ELasticsearch 负责日志分析和存储,Logstash负责日志收集,Kibana 负责界面展示。
EFK 是Elasticsearch,FileBeat,Kibana的集合。与ELK不同的是,FileBeat替代了Logstash,负责日志收集
Logstash 数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置
Filebeat 轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 shipper 端的第一选择
# Elasticsearch特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上
4)支持插件机制,分词插件(中文分词)、同步插件、可视化插件(kibana)等
# 国内外优秀案例
github 2013年全部换成es作为搜索引擎
# 我们应用场景 只要涉及到大数据量搜索,全文检索,都可以使用
# Elasticsearch索引到底能处理多大数据
单一索引的极限取决于存储索引的硬件、索引的设计、如何处理数据以及你为索引备份了多少副本。
通常来说,一个Lucene索引(也就是一个elasticsearch分片,一个es索引默认5个分片)不能处理多于21亿篇文档,或者多于2740亿的唯一词条。但达到这个极限之前,我们可能就没有足够的磁盘空间了!
当然,一个分片如何很大的话,读写性能将会变得非常差
安装部署
二进制部署
环境准备
#系统优化
vim /etc/security/limits.conf #断开连接或者重新登录生效
# End of file
* soft nofile 65535
* hard nofile 65535
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
* soft memlock unlimited
* hard memlock unlimited
vim /etc/sysctl.conf
vm.max_map_count=655360
vm.swappiness=0
sysctl -p
ulimit -n
# 下载tar包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
useradd elastic
tar xf elasticsearch-7.13.0-linux-x86_64.tar.gz
mv elasticsearch-7.13.0 /usr/local/elasticsearch
chown -R elastic:elastic /usr/local/elasticsearch
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-linux-x86_64.tar.gz
tar xf kibana-7.13.0-linux-x86_64.tar.gz
mv kibana-7.13.0-linux-x86_64 /usr/local/kibana
chown -R elastic:elastic /usr/local/kibana
# 数据位置
mkdir /data/elastic/logs -p
chown -R elastic:elastic /data/elastic/
简单配置文件
# 简单的配置修改
# elasticsearch地址修改
vim /usr/local/elasticsearch/config/elasticsearch.yml
...
network.host: 127.0.0.1
...
# jvm内存调整(一般建议为物理内存的一半)
vim /usr/local/elasticsearch/config/jvm.options
...
-Xms512m
-Xmx512m
...
# kibana简单配置文件
vim /usr/local/kibana/config/kibana.yml
...
server.port: 5601 # kibana默认监听端 口
server.host: "0.0.0.0" # 设置地址
elasticsearch.hosts: ["http://localhost:9200"] # kibana 丛 coordinating节点获取数据 可以多个
i18n.locale: "zh-CN" # 设置中文
...
启动
# 切换用户(elasticsearch和kibana默认是不能使用root用户启动的)
su - elastic
# 启动elasticsearch
/usr/local/elasticsearch/bin/elasticsearch -d
# 如果使用了root用户启动的话再次启动需要删除下面的文件
rm -f /usr/local/elasticsearch/config/elasticsearch.keystore
# 启动kibana(没有-d参数,可以用nohup或者写启动脚本)
/usr/local/kibana/bin/kibana &
# 浏览器访问kibana
https://IP:5601
RPM 包安装
yum install java -y
# 下载rpm包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-x86_64.rpm
# 安装
rpm -ivh elasticsearch-7.13.0-x86_64.rpm
rpm -ivh kibana-7.13.0-x86_64.rpm
# 配置文件位置,配置修改参考二进制部署
/etc/elasticsearch/
/etc/kibana/
systemctl start elasticsearch.service
systemctl start kibana.service
ES 集群部署
部署集群
规划
| 名称 | IP 地址 |
|---|
| node1 | 192.168.0.21 |
| node2 | 192.168.0.21 |
| node3 | 192.168.0.21 |
系统优化
# 三台主机都要操作
vim /etc/security/limits.conf # 断开连接或者重新登录生效
# End of file
* soft nofile 65535
* hard nofile 65535
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
* soft memlock unlimited
* hard memlock unlimited
vim /etc/sysctl.conf
vm.max_map_count=655360
vm.swappiness=0
sysctl -p
ulimit -n
下载软件
# 三台主机都要操作
yum install java -y
useradd elastic
# elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
tar xf elasticsearch-7.13.0-linux-x86_64.tar.gz
mv elasticsearch-7.13.0 /usr/local/elasticsearch
chown -R elastic:elastic /usr/local/elasticsearch
# kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-linux-x86_64.tar.gz
tar xf kibana-7.13.0-linux-x86_64.tar.gz
mv kibana-7.13.0-linux-x86_64 /usr/local/kibana
chown -R elastic:elastic /usr/local/kibana
# 数据位置
mkdir /data/elastic/logs -p
chown -R elastic:elastic /data/elastic/
配置文件
# node1
grep ^[a-z] /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-application # 集群名称
node.name: node-1 # 节点名称
path.data: /data/elastic # 数据存储路径
path.logs: /data/elastic/logs # 日志存储路径
network.host: 192.168.0.21 # 监听在本地哪个地址上
http.port: 9200 # 监听端口
discovery.seed_hosts: ["192.168.0.21", "192.168.0.22", "192.168.0.23"] # 集群主机列表
cluster.initial_master_nodes: ["192.168.0.21", "192.168.0.22", "192.168.0.23"] # 仅第一次启动集群时进行选举
# node2
grep ^[a-z] /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-application
node.name: node-2
path.data: /data/elastic
path.logs: /data/elastic/logs
network.host: 192.168.0.22
http.port: 9200
discovery.seed_hosts: ["192.168.0.21", "192.168.0.22", "192.168.0.23"]
cluster.initial_master_nodes: ["192.168.0.21", "192.168.0.22", "192.168.0.23"]
# node3
grep ^[a-z] /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: my-application
node.name: node-3
path.data: /data/elastic
path.logs: /data/elastic/logs
network.host: 192.168.0.23
http.port: 9200
discovery.seed_hosts: ["192.168.0.21", "192.168.0.22", "192.168.0.23"]
cluster.initial_master_nodes: ["192.168.0.21", "192.168.0.22", "192.168.0.23"]
# 优化
## 锁定物理内存地址,避免es使用swap交换分区,频繁 的交换,会导致IOPS变高
bootstrap.memory_lock: true
## jvm参数 可根据服务器内存大小,修改为合适的值。一般设置为服 务器物理内存的一半最佳,但最大不能超过32G
vim /usr/local/elasticsearch/config/jvm.options
-Xms31g # 最小堆内存
-Xmx31g # 最大堆内存
# 每天1TB左右的数据量的服务器配置
# 16C 64G 6T 3台ECS
开启密码
# node1 机器上操作
# 生成证书和密钥 免交互的
/usr/local/elasticsearch/bin/elasticsearch-certutil ca --out /usr/local/elasticsearch/config/elastic-stack-ca.p12 --pass ''
/usr/local/elasticsearch/bin/elasticsearch-certutil cert --ca /usr/local/elasticsearch/config/elastic-stack-ca.p12 --pass '' --ca-pass '' --out /usr/local/elasticsearch/config/elastic-certificates.p12
# 非免交互的在生成证书和密钥的过程,直接回车即可,使用默认的名字和空密码
# 发送证书给其他机器
scp -rp /usr/local/elasticsearch/config/elastic-stack-ca.p12 [email protected]:/usr/local/elasticsearch/config/
scp -rp /usr/local/elasticsearch/config/elastic-certificates.p12 [email protected]:/usr/local/elasticsearch/config/
# 保证权限
chown -R elastic:elastic /usr/local/elasticsearch
# 三台机器上都追加该配置信息
vim /usr/local/elasticsearch/config/elasticsearch.yml
xpack.security.enabled: true #开启安全功能
xpack.security.transport.ssl.enabled: true #开启传输的时候通过SSL加密功能
xpack.security.transport.ssl.verification_mode: certificate #认证模式是证书认证
xpack.security.transport.ssl.keystore.path: /usr/local/elasticsearch/config/elastic-certificates.p12 # 证书位置
xpack.security.transport.ssl.truststore.path: /usr/local/elasticsearch/config/elastic-certificates.p12 # 证书位置
# 如果节点证书配置密码的话,这里要加入密码库
/usr/local/elasticsearch/bin/elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
/usr/local/elasticsearch/bin/elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password
# 全部机器都启动 elasticsearch
su - elastic
/usr/local/elasticsearch/bin/elasticsearch -d
# node1 机器上操作
# 初始化密码
/usr/local/elasticsearch/bin/elasticsearch-setup-passwords interactive
# 上面只是elasticsearch开启了密码
启动kibana
# 将kibana安装在node1上
# 将证书拷贝到kibana相关目录(还是在elastic用户下操作)
su - elastic
cp -rp /usr/local/elasticsearch/config/elastic-* /usr/local/kibana/config
# 有两种解决认证的方式
## 将用户名密码写在配置文件中 设置密码,账户一定要是elastic,密码也一定要是之前设置的密码 (不推荐)
vim /usr/local/kibana/config/kibana.yml
elasticsearch.username: "elastic"
elasticsearch.password: "111111"
elasticsearch.ssl.certificate: /usr/local/kibana/config/elastic-certificates.p12
elasticsearch.ssl.key: /usr/local/kibana/config/elastic-stack-ca.p12
## 通过keystore配置加密的用户名密码信息
vim /usr/local/kibana/config/kibana.yml
elasticsearch.ssl.certificate: /usr/local/kibana/config/elastic-certificates.p12
elasticsearch.ssl.key: /usr/local/kibana/config/elastic-stack-ca.p12
# 用户名是elastic 密码是设置的密码
/usr/local/kibana/bin/kibana-keystore create
/usr/local/kibana/bin/kibana-keystore add elasticsearch.username
/usr/local/kibana/bin/kibana-keystore add elasticsearch.password
# 配置文件
grep ^[a-z] config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.0.21:9200", "http://192.168.0.22:9200", "http://192.168.0.23:9200"]
i18n.locale: "zh-CN"
elasticsearch.ssl.certificate: /usr/local/kibana/config/elastic-certificates.p12
elasticsearch.ssl.key: /usr/local/kibana/config/elastic-stack-ca.p12
xpack.reporting.encryptionKey: "a_random_string"
xpack.security.encryptionKey: "something_at_least_32_characters"
# 启动 nohup
/usr/local/kibana/bin/kibana &
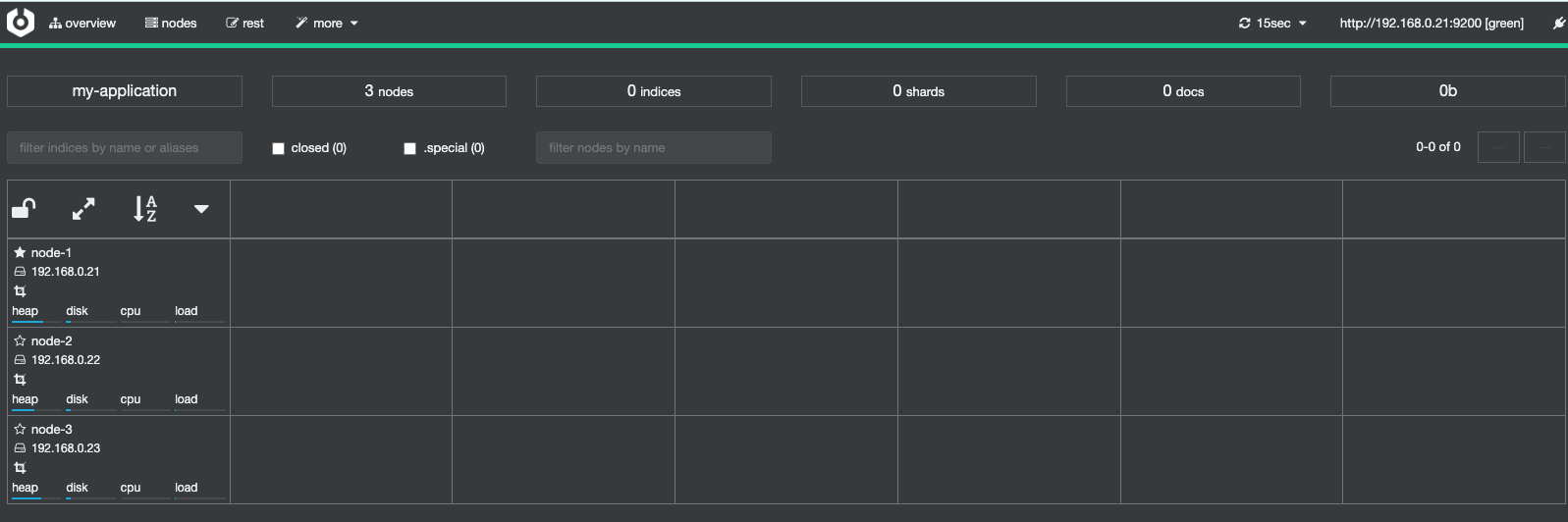
健康状态
Cluster Health 获取集群的健康状态,整个集群状态
包括以下三种:
1.green 健康状态,指所有主副分片都正常分配
2.yellow 指所有主分片都正常分配,但是有副本分 片未正常分配
3.red 有主分片未分配,表示索引不完备,写可能有 问题。(但不代表不能存储数据和读取数据)
检查 ES 集群是否正常运行,可以通过 curl、Cerebro 两种方式
# 方式一
curl 192.168.0.22:9200/_cluster/health?pretty=true
# 方式二 Cerebor
https://github.com/lmenezes/cerebro/releases
rpm -ivh cerebro-0.9.4-1.noarch.rpm
# 修改存放数据的地方
vim /etc/cerebro/application.conf
data.path: "/var/lib/cerebro/cerebro.db"
systemctl start cerebro
netstat -lntup |grep 9000
# 浏览器访问
192.168.0.22:9000 # 然后填入 es的地址 如 192.168.0.22:9200

集群节点类型
Cluster State
集群相关的数据称为cluster state会存储在每个节点中,主要有如下信息:
1)节点信息,比如节点名称、节点连接地址等
2)索引信息,比如索引名称、索引配置信息等
Master
集群中只能有一个 节点, 节点 用于控制整个集群的操作;
主要维护cluster state,当有新数据产生后,Master会将数据同步给其他Node节点;
master节点是通过选举产生的,可以通过 node.master:true 指定为Master节点,默认是true
当使用API创建索引 Cluster state 则会发生变化,由Master同步至其他Node节点
Data
存储数据的节点即为data节点,默认节点都是data类型,配置node.data:true
当创建索引后,索引创建的数据会存储至某个节点, 能够存储数据的节点,称为 data 节点
Coordinating
处理请求的节点即为coordinating节点,该节点为所有节点的默认角色,不能取消
coordinating节点主要将请求路由到正确的节点处理。比如创建索引的请求会由coordinating路由到master节点处理,当配置node.master:false、node.data:false则为coordinating节点
可视化界面
# elasticsearch-head
https://github.com/mobz/elasticsearch-head
cd elasticsearch-head
npm install
npm run start
http://localhost:9100/
# 跨域的配置---》es的config目录下的elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
# 可以不用安装也可以使用,谷歌浏览器插件中有 elasticsearch-head
# kibana 安装如上集群,可以操作es
基本概念
索引
索引(index)是 Elasticsearch 对逻辑数据的逻辑存储,所以它可以 分为更小的部分
可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索 引准备的,特别是它不存储原始值
Elasticsearch 可以把索引存放在一台机器或者分散在多台服务器上, 每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)
文档
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
存储在 Elasticsearch 中的主要实体叫文档(document)。用关系型数 据库来类比的话,一个文档相当于数据库表中的一行记录
Elasticsearch 和 MongoDB 中的文档类似,都可以有不同的结构,但 Elasticsearch 的文档中,相同字段必须有相同类型
文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字 段叫多值字段(multivalued)。 每个字段的类型,可以是文本、数值、日期等。 字段类型也可以是复杂类型,一个字段包含其他子文档或者数组
映射
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪 些词条又会被过滤,这种行为叫做映射(mapping) 一般由用户自己定义规则
文档类型
在 Elasticsearch 中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评论
每个文档可以有不同的结构
不同的文档类型不能为相同的属性设置不同的类型。例如,在同一索引 中的所有文档类型中,一个叫 title 的字段必须具有相同的类型
倒排索引
# 面试es重点:倒排索引 keywords和text区别
keyword不分词,直接建索引
text要分词,再建索引
# 倒排索引:通过关键字简历索引查询文档,存的时候对关键字建立索引
文章id ---> 文章内容 ---> 正向索引
关键词1
关键词2 ---> 文章内容1,文章内容2 ---> 倒排索引
关键词3
# 总结
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引
- 搜索引擎原理就是建立反向索引
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份
- Elasticsearch 一个典型应用就是 ELK 日志分析系统
基本的使用
Elasticsearch是通过RUSTful API来操作数据的,包括CRUD,创建索引,删除索引等
索引操作
在 Lucene 中,创建索引是需要定义字段名称以及字段的类型的,在 Elasticsearch 中提供了非结构化的索引,就是不需要创建索引结构,即可写入 数据到索引中,实际上在 Elasticsearch 底层会进行结构化操作,此操作对用户是透明的
# 索引对等mysql的数据库 在kibana中操作
# 新增索引 建立一个 test 索引,有5个分片,每个分片一个副本
PUT test
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
# 查看索引
# 获取lqz2索引的配置信息
GET test/_settings
# 获取所有索引的配置信息
GET _all/_settings
GET _settings
# 修改索引(一般不改)
PUT test/_settings
{
"number_of_replicas": 2
}
# 删除索引
DELETE test
映射管理
# 对比mysql中建表语句
# es 6.x之前,一个索引下可以有多个类型 ---> 一个库下可以有多个表,6.x 可以使用多个类型,但不能创建了
# es 6.x以后,一个索引下只能有一个类型 --->一个库下只能有一个表
# 在es中,索引没有,类型没有,可以直接插入文档--》插入文档后,自动创建索引和类型,
# mysql必须先建库,再建表,再插入数据
# 创建类型
## 6.x之前的建立类型,给books索引,建立一个类型book类型,无论索引是否存在
PUT books
{
"mappings": {
"book":{
"properties":{
"title":{
"type":"text"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
}
## 6.x以后的建立类型 ---> 不能建多个类型了,不需要指定类型,默认叫 _doc
PUT books
{
"mappings": {
"properties":{
"title":{
"type":"text"
},
"price":{
"type":"integer"
},
"addr":{
"type":"keyword"
},
"company":{
"properties":{
"name":{"type":"text"},
"company_addr":{"type":"text"},
"employee_count":{"type":"integer"}
}
},
"publish_date":{"type":"date","format":"yyy-MM-dd"}
}
}
}
# python 没有基础数据类型 ---> 对象 ---> 整形可以无限长
# 字段类型 字段数据类型
string类型:text,keyword
数字类型:byte(int8->一个字节),short(int16->2个字节),integer(int32->4个字节),long(int64-->8个字节),float(float32),double(float64)
日期类型:data
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表)
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
# 字段参数 ---> 字段有参数
store 值为yes表示存储,no表示不存储,默认为yes all
index yes表示分析,no表示不分析,默认为true text
null_value 如果字段为空,可以设置一个默认值,比如"NA"(传过来为空,不能搜索,na可以搜索) all
analyzer 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 all
include_in_all 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false all
format 时间格式字符串模式 date
###### 查看映射 mapping 类型
#查看books索引的mapping
GET books/_mapping
#获取所有的mapping
GET _all/_mapping
#### 插入文档
PUT books/_doc/1
{
"title":"大头儿子小偷爸爸",
"price":100,
"addr":"北京天安门",
"company":{
"name":"我爱北京天安门",
"company_addr":"我的家在东北松花江傻姑娘",
"employee_count":10
},
"publish_date":"2019-08-19"
}
# 测试数据2
PUT books/_doc/2
{
"title":"白雪公主和十个小矮人",
"price":"99",
"addr":"黑暗森里",
"company":{
"name":"我的家乡在上海",
"company_addr":"朋友一生一起走",
"employee_count":10
},
"publish_date":"2018-05-19"
}
文档的增删改查
### 文档增
PUT test/_doc/1
{
"name":"顾老二",
"age":30,
"from": "gu",
"desc": "皮肤黑、武器长、性格直",
"tags": ["黑", "长", "直"]
}
### 文档改
### 方式一:覆盖更新
PUT test/_doc/1
{
"name":"lxx",
"age":30
}
### 方式二:真更新
POST test/_doc/1/_update
{
"doc": {
"desc": "皮肤很黄,武器很长,性格很直",
"tags": ["很黄","很长", "很直"]
}
}
POST test/_update/1
{
"doc": {
"desc": "xx,yy,zz",
"tags": ["很黄","很长", "很直"]
}
}
### 文档删
DELETE test/_doc/1
## 文档查(最复杂)
### 方式一:根据id
GET test/_doc/1
### 方式二:根据查询字符串
GET test/_search?q=from:gu
GET test/_search?q=age:29
#### 方式三:结构化查询(常用,功能丰富)
GET book/_search
{
"query": {
"match": {
"name": "我爱北京天安门天安门上太阳升"
}
}
}
#### 面试重点:term和match的区别
term 代表完全匹配,不进行分词器分析
term 查询的字段需要在mapping的时候定义好,否则可能词被分词。传入指定的字符串,查不到数据
match
match的查询词会被分词,会把要搜索的词分词 ---> 搜索
存的时候,如果是text类型,会分词,建索引存储
es是个存数据的地方
mysql ---> 存到es
pymysql 取出mysql数据 ---> 存到es中
查询数据
常用接口
curl http://10.0.0.51:9200/_cluster/health?pretty # 查看集群健康情况