golang基础-切片
切片
切片(Slice)与数组一样,也是可以容纳若干类型相同的元素的容器。
与数组不同的是,无法通过切片类型来确定其值的长度。
每个切片值都会将数组作为其底层数据结构。
切片(slice)是对数组的一个连续片段的引用,所以切片是一个引用类型。
支持自动扩容,内部结构包含地址、长度和容量。
定义
var name []T
例子
// 定义切片
var s1 []int
var s2 []string
fmt.Println(s1)
fmt.Println(s2)
长度和容量
切片有长度和容量,可以通过 len() 函数求长度, cap() 函数求切片的容量
切片的底层是数组,所以数组通过切片表达式可以得到切片。
切片表达式中的low和high表示一个索引范围,左包含,右不包含
长度=high-low
容量是从数组low到数组后面所有
func main() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s)) // s:[2 3] len(s):2 cap(s):4
}
make()构造切片
上述都是通过数组来创建切片
下面使用动态创建一个切片,需要使用内置函数 make() 函数
make([]T,size,cap)
- T:切片的元素类型
- size:切片中元素的数量
- cap:切片的容量
a := make([]int,2,10)
fmt.Println(a,len(a),cap(a)) // [0 0],2,10
切片的本质
是对底层数组的封装,包含三个信息:
底层数组的指针、切片的长度(len)和切片的容量(cap)。
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。
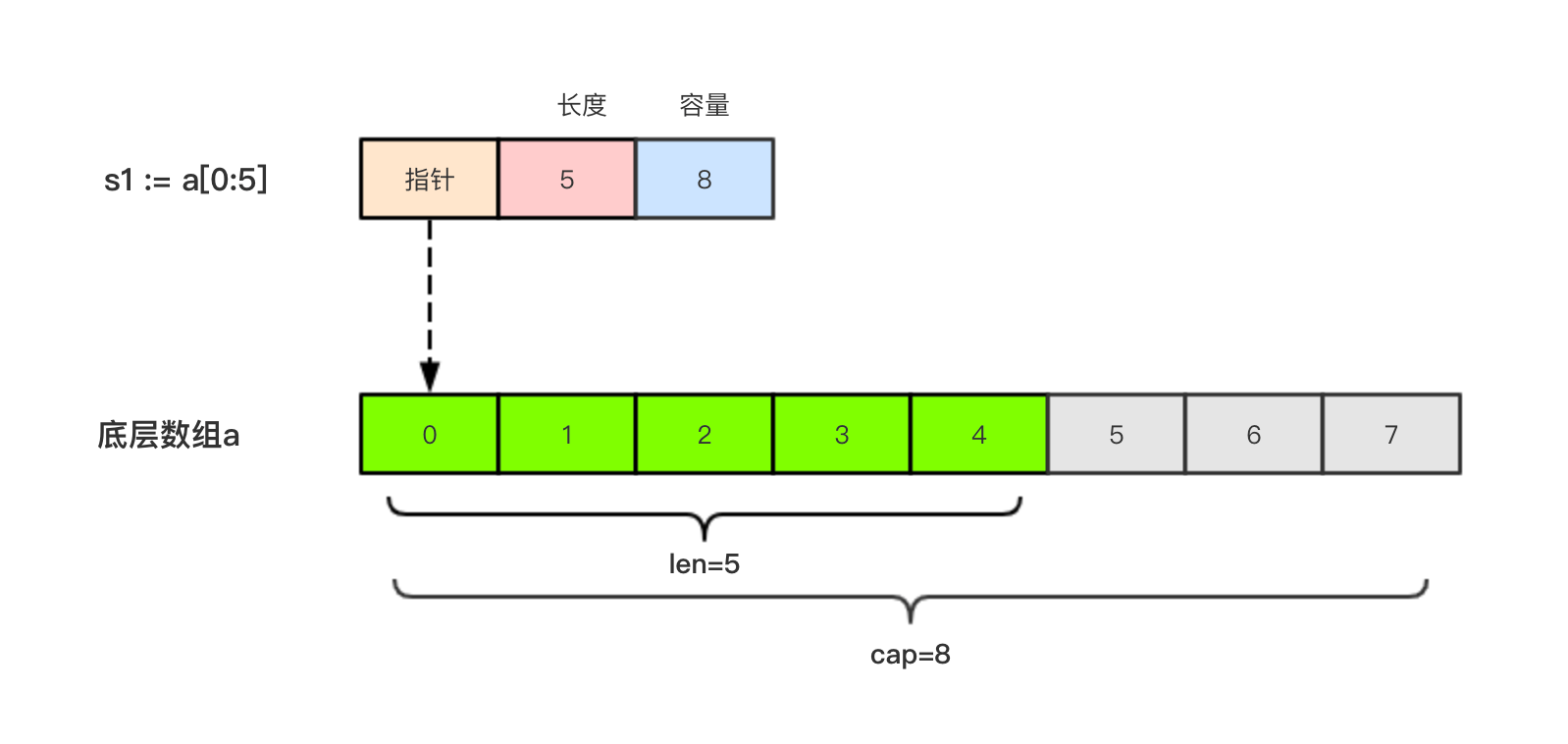
切片s2 := a[3:6],相应示意图如下:
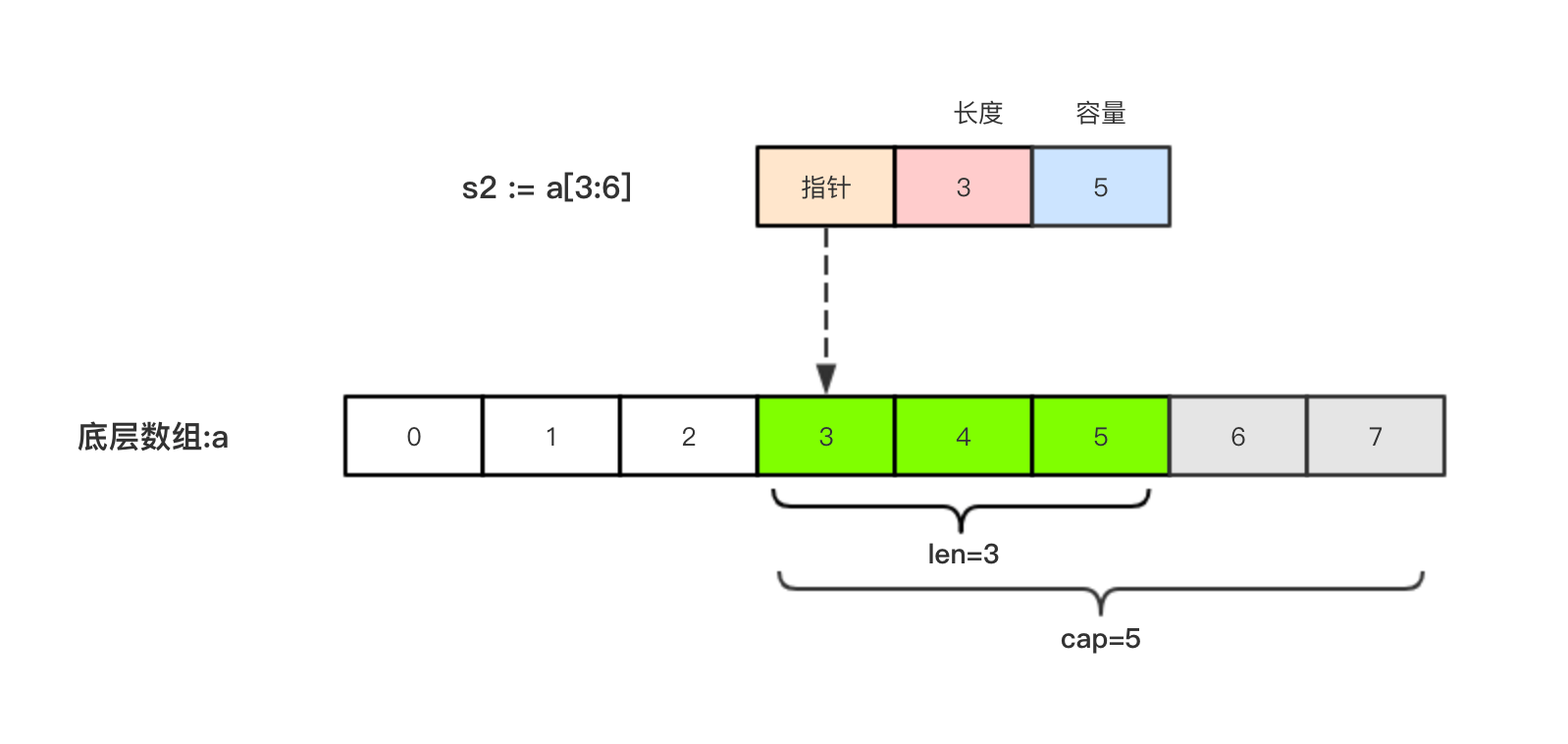
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
赋值拷贝
拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容
func main() {
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
}
遍历
遍历方式和数组是一致的,支持索引遍历和for range遍历
func main() {
s := []int{1, 3, 5}
for i := 0; i < len(s); i++ {
fmt.Println(i, s[i])
}
for index, value := range s {
fmt.Println(index, value)
}
}
添加元素
内置 append() 函数可以为切片添加元素,可以一次添加一个元素,多个元素,以及另一个切片中的元素(后面加…)
func main(){
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
}
**注意:**通过var声明的零值切片可以在append()函数直接使用,无需初始化。
每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
举个例子:
func main() {
//append()添加元素和切片扩容
var numSlice []int
for i := 0; i < 10; i++ {
numSlice = append(numSlice, i)
fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice)
}
}
从上面的结果可以看出:
append()函数将元素追加到切片的最后并返回该切片。- 切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍。
append()函数还支持一次性追加多个元素。 例如:
var citySlice []string
// 追加一个元素
citySlice = append(citySlice, "北京")
// 追加多个元素
citySlice = append(citySlice, "上海", "广州", "深圳")
// 追加切片
a := []string{"成都", "重庆"}
citySlice = append(citySlice, a...)
fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]
扩容策略
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
copy()复制切片
使用内置函数 copy() 复制切片,可以将一个切片的数据复制到另一个切片空间中,使用格式
copy(destSlice, srcSlice []T)
- srcSlice: 数据来源切片
- destSlice: 目标切片
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}
删除元素
切片中没有删除元素的专用方法,我们可以使用切片本身的特性来删除元素
func main() {
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
}
总结一下就是:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
请使用内置的sort包对数组var a = [...]int{3, 7, 8, 9, 1}进行排序
var a = [...]int{3, 7, 8, 9, 1}
sort.Ints(a[:])
fmt.Println(a)
其他操作
package main
import (
"fmt"
"sort"
)
func main() {
// 在开头位置插入元素方法
/* var arr = []int{1, 2, 3, 4, 5}
var val = 6
fmt.Println(append([]int{val}, arr...))*/
// 在任意位置插入元素
/* var arr = []int{1, 2, 3, 4, 5}
var val = 6
var index = 2
var s1 = arr[:index]
var s2 = arr[index:]
arr = append(s1, append([]int{val}, s2...)...)
fmt.Println(arr)*/
}
排序和比较
package main
import (
"fmt"
"slices"
)
func main() {
arr := []int{3, 7, 4, 6, 8, 1}
slices.Sort(arr)
fmt.Println(arr)
slices.SortFunc(arr, func(a, b int) int { // 自定义排序方式
return b - a
})
fmt.Println(arr)
type User struct {
Age int
Height float32
}
brr := []*User{&User{18, 1.8}, &User{25, 1.7}}
slices.SortFunc(brr, func(a, b *User) int {
if a.Height > b.Height {
return 1
} else if b.Height < a.Height {
return -1
} else {
return 0
}
})
fmt.Println(brr[0].Height, brr[1].Height)
fmt.Println("最大者", slices.Max(arr))
fmt.Println("最小者", slices.Min(arr))
fmt.Println("包含", slices.Contains(arr, 5))
crr := make([]int, len(arr))
copy(crr, arr) // 最多只能拷贝 len(crr) 个元素,性能比自己写 for 循环要高很多
fmt.Println(crr)
fmt.Println("相等", slices.Equal(arr, crr))
arr[0]++
fmt.Println("相等", slices.Equal(arr, crr))
drr := brr // 共享底层空间
fmt.Println("相等", slices.Equal(brr, drr))
brr[0].Age++
fmt.Println("相等", slices.Equal(brr, drr))
}
nil
在Go语言中,布尔类型的零值(初始值)为 false,数值类型的零值为 0,字符串类型的零值为空字符串"",而指针、切片、映射、通道、函数和接口的零值则是 nil。
nil和其他语言的null是不同的。
nil 标识符是不能比较的
package main
import (
"fmt"
)
func main() {
//invalid operation: nil == nil (operator == not defined on nil)
fmt.Println(nil==nil)
}
nil 不是关键字或保留字
nil 并不是Go语言的关键字或者保留字,也就是说我们可以定义一个名称为 nil 的变量,比如下面这样:
//但不提倡这样做
var nil = errors.New("my god")
nil 没有默认类型
package main
import (
"fmt"
)
func main() {
//error :use of untyped nil
fmt.Printf("%T", nil)
print(nil)
}
不同类型 nil 的指针是一样的
package main
import (
"fmt"
)
func main() {
var arr []int
var num *int
fmt.Printf("%p\n", arr)
fmt.Printf("%p", num)
}
nil 是 map、slice、pointer、channel、func、interface 的零值
package main
import (
"fmt"
)
func main() {
var m map[int]string
var ptr *int
var c chan int
var sl []int
var f func()
var i interface{}
fmt.Printf("%#v\n", m)
fmt.Printf("%#v\n", ptr)
fmt.Printf("%#v\n", c)
fmt.Printf("%#v\n", sl)
fmt.Printf("%#v\n", f)
fmt.Printf("%#v\n", i)
}
零值是Go语言中变量在声明之后但是未初始化被赋予的该类型的一个默认值。
不同类型的 nil 值占用的内存大小可能是不一样的
package main
import (
"fmt"
"unsafe"
)
func main() {
var p *struct{}
fmt.Println( unsafe.Sizeof( p ) ) // 8
var s []int
fmt.Println( unsafe.Sizeof( s ) ) // 24
var m map[int]bool
fmt.Println( unsafe.Sizeof( m ) ) // 8
var c chan string
fmt.Println( unsafe.Sizeof( c ) ) // 8
var f func()
fmt.Println( unsafe.Sizeof( f ) ) // 8
var i interface{}
fmt.Println( unsafe.Sizeof( i ) ) // 16
}
具体的大小取决于编译器和架构
new和make
make 关键字的主要作用是创建 slice、map 和 Channel 等内置的数据结构,而 new 的主要作用是为类型申请一片内存空间,并返回指向这片内存的指针。
- make 分配空间后,会进行初始化,new分配的空间被清零
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 可以分配任意类型的数据;