golang基础-函数
函数
组织好的,可重复使用的、用于执行指定任务的代码块
支持函数、匿名函数和闭包,并且在go中属于 “一等公民”,函数可以像其他数据类型一样被传递、赋值、返回和操作
定义
函数使用 func 关键字定义,格式:
func 函数名(参数)(返回值){
函数体
}
其中:
- 函数名:由字母、数字、下划线组成。但函数名的第一个字母不能是数字。在同一个包内,函数名也称不能重名。
- 参数:参数由参数变量和参数变量的类型组成,多个参数之间使用
,分隔。 - 返回值:返回值由返回值变量和其变量类型组成,也可以只写返回值的类型,多个返回值必须用
()包裹,并用,分隔。 - 函数体:实现指定功能的代码块。
定义一个两数求和函数
func intSum(x int, y int) int {
return x + y
}
函数的参数和返回值都是可选的,可以不设置
func sayHello() {
fmt.Println("hello")
}
调用
函数的调用可以直接通过 函数名() 进行调用,例如
func main() {
sayHello()
ret := intSum(1,1)
fmt.Println(ret)
}
调用的函数有返回值时,可以不接收其返回值
参数
类型简写
func intSum(x, y int) int {
return x + y
}
形参和实参
在定义函数时函数名后面括号中的变量叫做形式参数(简称形参)。形式参数只在函数调用时才会生效,函数调用结束后就会被销毁,在函数未被调用时,函数的形参并不占用实际的存储单元,也没有实际值。
形式参数会作为函数的局部变量来使用。
声明在函数中的参数叫形式参数,a和b就是形参
func add(a, b int) {
fmt.Println(a + b)
}
但当调用函数,传递过来的变量就是函数的实参,函数可以通过两种方式来传递参数:
值传递 指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递
是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
注意1:无论是值传递,还是引用传递,传递给函数的都是变量的副本,不过,值传递是值的拷贝。引用传递是地址的拷贝,一般来说,地址拷贝更为高效。而值拷贝取决于拷贝的对象大小,对象越大,则性能越低。
注意2:map、slice、chan、指针、interface默认以引用的方式传递。
可变参数
函数的参数数量不是固定的,后面的类型是固定的
可变参数本质上就是 slice 。 只能有一个,且必须是最后一个
在参数赋值时可以不用用一个一个的赋值,可以直接传递一个数组或者切片。
例子:
func add3(x ...int) {
fmt.Println(x, reflect.TypeOf(x)) // 是一个切片
var ret int
for _, v := range x {
ret += v
}
fmt.Println(ret)
}
// 使用
func main() {
add3(1, 2, 3)
add3(1, 2, 3, 4)
}
可以搭配固定参数使用,可变参数需要放到最后,且只能有一个
func intSum3(x int, y ...int) int {
fmt.Println(x, y)
sum := x
for _, v := range y {
sum = sum + v
}
return sum
}
func main(){
ret5 := intSum3(100)
ret6 := intSum3(100, 10)
ret7 := intSum3(100, 10, 20)
ret8 := intSum3(100, 10, 20, 30)
fmt.Println(ret5, ret6, ret7, ret8) //100 110 130 160
}
返回值
return关键字向外输出返回值。
func add5(a, b int) int {
return a + b // 函数的返回语句 函数终止语句
}
返回值为空
func printInfo(name string, age int) {
fmt.Printf("姓名:%s,年龄:%d\n", name, age)
return // 等同于不写return 返回空
}
多返回值
函数如果有多个返回值时必须用()将所有返回值包裹起来
func calc(x, y int) (int, int) {
sum := x + y
sub := x - y
return sum, sub
}
返回值命名
函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过return关键字返回。
func calc(x, y int) (sum, sub int) {
sum = x + y
sub = x - y
return
}
返回值补充
当我们的一个函数返回值类型为slice时,nil可以看做是一个有效的slice,没必要显示返回一个长度为0的切片。
func someFunc(x string) []int {
if x == "" {
return nil // 没必要返回[]int{}
}
...
}
作用域
一个变量(常量、类型或函数)在程序中都有一定的作用范围,称之为
作用域。
根据变量定义位置的不同,可以分为以下三个类型:
- 函数内定义的变量称为局部变量
- 函数外定义的变量称为全局变量
- 函数定义中的变量称为形式参数
全局变量
定义在函数外部的变量,在整个程序运行周期内都有效,在函数中可以访问到全局变量
全局变量声明必须以 var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
package main
import "fmt"
var y = 10 // 全局变量 适用于所有范围内
var x = 5
func foo1() {
var x = 100
fmt.Printf("foo1的x: %d\n", x)
fmt.Printf("foo1的y: %d\n", y)
y = 1
}
func main() {
//foo1()
//fmt.Printf("main函数的y: %d\n", y)
var b = true
if b {
var x = 666
fmt.Println(x)
}
fmt.Println(x)
}
局部变量
在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,函数的参数和返回值变量都属于局部变量。
Go语言程序中全局变量与局部变量名称可以相同,但是函数体内的局部变量会被优先考虑。
func testLocalVar() {
//定义一个函数局部变量x,仅在该函数内生效
var x int64 = 100
fmt.Printf("x=%d\n", x)
}
func main() {
testLocalVar()
fmt.Println(x) // 此时无法使用变量x
}
if 和 for 具备开辟作用域的能力
func testLocalVar2(x, y int) {
fmt.Println(x, y) //函数的参数也是只在本函数中生效
if x > 0 {
z := 100 //变量z只在if语句块生效
fmt.Println(z)
}
//fmt.Println(z)//此处无法使用变量z
}
func testLocalVar3() {
for i := 0; i < 10; i++ {
fmt.Println(i) //变量i只在当前for语句块中生效
}
//fmt.Println(i) //此处无法使用变量i
}
函数类型和变量
定义函数类型
我们可以使用type关键字来定义一个函数类型,具体格式如下:
type calculation func(int, int) int
calculation 是一个函数类型
func add(x, y int) int {
return x + y
}
func sub(x, y int) int {
return x - y
}
add和sub都能赋值给calculation类型的变量。
var c calculation
c = add
函数类型变量
声明函数类型的变量并且为该变量赋值:
func add(x, y int) int {
return x + y
}
func main() {
var c calculation // 声明一个calculation类型的变量c
c = add // 把add赋值给c
fmt.Printf("type of c:%T\n", c) // type of c:main.calculation
fmt.Println(c(1, 2)) // 像调用add一样调用c
f := add // 将函数add赋值给变量f
fmt.Printf("type of f:%T\n", f) // type of f:func(int, int) int
fmt.Println(f(10, 20)) // 像调用add一样调用f
}
高阶函数
函数作为参数
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
ret2 := calc(10, 20, add)
fmt.Println(ret2) //30
}
函数作为返回值
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}
package main
import (
"fmt"
"reflect"
"time"
)
/*
以函数作为参数
以函数作为返回值
*/
func timer(f func()) { // 完整的函数类型,需要带上形参 和返回值等信息
start := time.Now().Unix()
f()
end := time.Now().Unix()
fmt.Println("时间花销:", end-start)
}
func addT(x, y int) int {
time.Sleep(1 * time.Second)
return x + y
}
func timer2(f func(int, int) int, x int, y int) int {
start := time.Now().Unix()
res := f(x, y)
end := time.Now().Unix()
fmt.Println("时间花销:", end-start)
return res
}
func outer() func(int, int) int {
inner := func(x, y int) int {
fmt.Println("内部inner")
return x + y
}
return inner
}
func main() {
timer(bar)
fmt.Println(reflect.TypeOf(addT)) // func(int, int) int
res := timer2(addT, 1, 2)
fmt.Println(res)
res2 := outer()(9, 9)
fmt.Println(res2)
}
匿名函数
匿名函数就是没有函数名的函数,匿名函数的定义格式如下:
func(参数)(返回值){
函数体
}
匿名函数因为没有函数名,所以没办法像普通函数那样调用,所以匿名函数需要保存到某个变量或者作为立即执行函数:
func main() {
// 将匿名函数保存到变量
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 通过变量调用匿名函数
//自执行函数:匿名函数定义完加()直接执行
func(x, y int) {
fmt.Println(x + y)
}(10, 20)
}
匿名函数多用于实现回调函数和闭包。
闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境。
package main
import "fmt"
func foo() func() {
var x = 100
// 嵌套函数
bar := func() {
fmt.Println("匿名函数")
fmt.Println(x) // 引用了一个外部非全局的自由变量 x bar 就是闭包函数
}
// 返回嵌套函数
return bar
}
func main() {
f := foo() // f 闭包函数
f()
}
例子2:
func adder2(x int) func(int) int {
return func(y int) int {
x += y
return x
}
}
func main() {
var f = adder2(10)
fmt.Println(f(10)) //20
fmt.Println(f(20)) //40
fmt.Println(f(30)) //70
f1 := adder2(20)
fmt.Println(f1(40)) //60
fmt.Println(f1(50)) //110
}
例子3
package main
import "fmt"
func foo() {
fmt.Println("foo 函数调用")
}
func counter(tFunc func()) func() int {
var count = 0
return func() int {
tFunc()
count += 1
return count
}
}
func main() {
foo := counter(foo)
foo()
foo()
n := foo()
fmt.Println(n)
}
例子4
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func main() {
jpgFunc := makeSuffixFunc(".jpg")
txtFunc := makeSuffixFunc(".txt")
fmt.Println(jpgFunc("test")) //test.jpg
fmt.Println(txtFunc("test")) //test.txt
}
例子5
func calc(base int) (func(int) int, func(int) int) {
add := func(i int) int {
base += i
return base
}
sub := func(i int) int {
base -= i
return base
}
return add, sub
}
func main() {
f1, f2 := calc(10)
fmt.Println(f1(1), f2(2)) //11 9
fmt.Println(f1(3), f2(4)) //12 8
fmt.Println(f1(5), f2(6)) //13 7
}
例子6
package main
import "fmt"
func makeFun(i int) func() {
return func() {
fmt.Println(i)
}
}
func main() {
var fn2 [10]func()
for i := 0; i < len(fn2); i++ {
fn2[i] = makeFun(i)
}
for _, f2 := range fn2 {
f2()
}
}
defer语句
defer 语句会将其后面跟随的语句进行延迟处理
特性
- 关键字 defer 用于注册延迟调用。
- 这些调用直到 return 前才被执。因此,可以用来做资源清理。
- 多个defer语句,按先进后出的方式执行。
- defer语句中的变量,在defer声明时就决定了。
defer的用途
- 关闭文件句柄
- 锁资源释放
- 数据库连接释放
执行时机
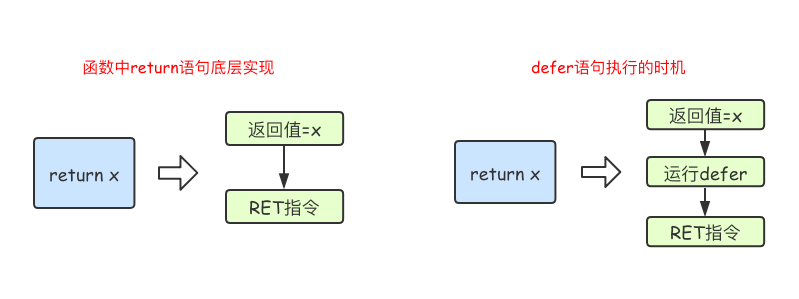
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示:
package main
import "fmt"
func main() {
/* // 先注册的后执行
defer fmt.Println("hello world 1...")
defer fmt.Println("hello world 2...")
defer fmt.Println("hello world 3...") // 先执行
fmt.Println("hello world...")*/
/* foo := func() {
fmt.Println("foo1")
}
defer foo() // foo1
foo = func() {
fmt.Println("foo2")
}*/
/* x := 10
defer func(a int) {
fmt.Println(a) // 10 会把函数体和形参都拷贝
}(x)
x++*/
x := 10
defer func() {
fmt.Println(x) // 11 内部的x和外部的x地址一样
}()
x++
}
package main
import "fmt"
func f1() int {
i := 5
defer func() {
i++
}()
return i
/*
rval = 5
defer
ret
*/
}
func f2() *int {
i := 5
defer func() {
i++
fmt.Printf(":::%p\n", &i)
}()
fmt.Printf(":::%p\n", &i)
return &i
}
func f3() (result int) {
defer func() {
result++
}()
return 5 // result = 5 defer_func ret result
}
func f4() (result int) {
defer func() {
result++
}()
return result // result = result(0) defer_func ret result
}
func f5() (r int) {
t := 5
defer func() {
t = t + 1
}()
return t // r=t=5 defer_func t=6 ret r
}
func f6() (r int) {
defer func(r int) {
r = r + 1
}(r)
return 5
}
func f7() (r int) {
defer func(x int) {
r = x + 1
}(r)
return 5
}
func main() {
//println(f1())
//println(*f2())
//println(f3())
//println(f4())
//println(f5())
//println(f6())
println(f7())
/*
return 语句
rval = xxx
ret
defer 语句发生在这俩条之间
rval = xxx
defer_func
ret
*/
}
异常处理
Go语言中使用 panic 抛出错误,recover 捕获错误。
异常的使用场景简单描述:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
panic:
- 内置函数
- 假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行
- 返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行
- 直到goroutine整个退出,并报告错误
recover:
- 内置函数
- 用来捕获panic,从而影响应用的行为
golang 的错误处理流程:当一个函数在执行过程中出现了异常或遇到 panic(),正常语句就会立即终止,然后执行 defer 语句,再报告异常信息,最后退出 goroutine。如果在 defer 中使用了 recover() 函数,则会捕获错误信息,使该错误信息终止报告。
注意:
- 利用recover处理panic指令,defer 必须放在 panic 之前定义,另外 recover 只有在 defer 调用的函数中才有效。否则当panic时,recover无法捕获到panic,无法防止panic扩散。
- recover 处理异常后,逻辑并不会恢复到 panic 那个点去,函数跑到 defer 之后的那个点。
- 多个 defer 会形成 defer 栈,后定义的 defer 语句会被最先调用。
package main
func main() {
test()
}
func test() {
defer func() {
if err := recover(); err != nil {
println(err.(string)) // 将 interface{} 转型为具体类型。
}
}()
panic("panic error!")
}
由于 panic、recover 参数类型为 interface{},因此可抛出任何类型对象。
func panic(v interface{})
func recover() interface{}
延迟调用中引发的错误,可被后续延迟调用捕获,但仅最后一个错误可被捕获:
package main
import "fmt"
func test() {
defer func() {
// defer panic 会打印
fmt.Println(recover())
}()
defer func() {
panic("defer panic")
}()
panic("test panic")
}
func main() {
test()
}
如果需要保护代码段,可将代码块重构成匿名函数,如此可确保后续代码被执 :
package main
import "fmt"
func test(x, y int) {
var z int
func() {
defer func() {
if recover() != nil {
z = 0
}
}()
panic("test panic")
z = x / y
return
}()
fmt.Printf("x / y = %d\n", z)
}
func main() {
test(2, 1)
}
除用 panic 引发中断性错误外,还可返回 error 类型错误对象来表示函数调用状态:
type error interface {
Error() string
}
标准库 errors.New 和 fmt.Errorf 函数用于创建实现 error 接口的错误对象。通过判断错误对象实例来确定具体错误类型。
package main
import (
"errors"
"fmt"
)
var ErrDivByZero = errors.New("division by zero")
func div(x, y int) (int, error) {
if y == 0 {
return 0, ErrDivByZero
}
return x / y, nil
}
func main() {
defer func() {
fmt.Println(recover())
}()
switch z, err := div(10, 0); err {
case nil:
println(z)
case ErrDivByZero:
panic(err)
}
}
Go实现类似 try catch 的异常处理:
package main
import "fmt"
func Try(fun func(), handler func(interface{})) {
defer func() {
if err := recover(); err != nil {
handler(err)
}
}()
fun()
}
func main() {
Try(func() {
panic("test panic")
}, func(err interface{}) {
fmt.Println(err)
})
}
如何区别使用 panic 和 error 两种方式?
惯例是:导致关键流程出现不可修复性错误的使用 panic,其他使用 error。
package main
import (
"fmt"
)
func defer_panic() {
defer fmt.Println(1)
var arr []int
n := 0
// defer fmt.Println(1 / n)
defer func() {
_ = arr[n]
_ = 1 / n
defer fmt.Println(2)
}()
defer fmt.Println(3)
}
func a() {
fmt.Println("func a ")
}
func b() {
defer func() {
err := recover()
if err != nil {
fmt.Println("func b err")
}
}()
panic("panic in b")
}
func c() {
fmt.Println("func c")
}
func main() {
a()
b()
c()
}