MySQL索引管理
索引的作用
提供了类似书中目录的作用,目的是为了优化查询
索引的种类
B树索引 # 默认使用的索引类型
Hash索引
R树索引
Full text
GIS
B 树算法
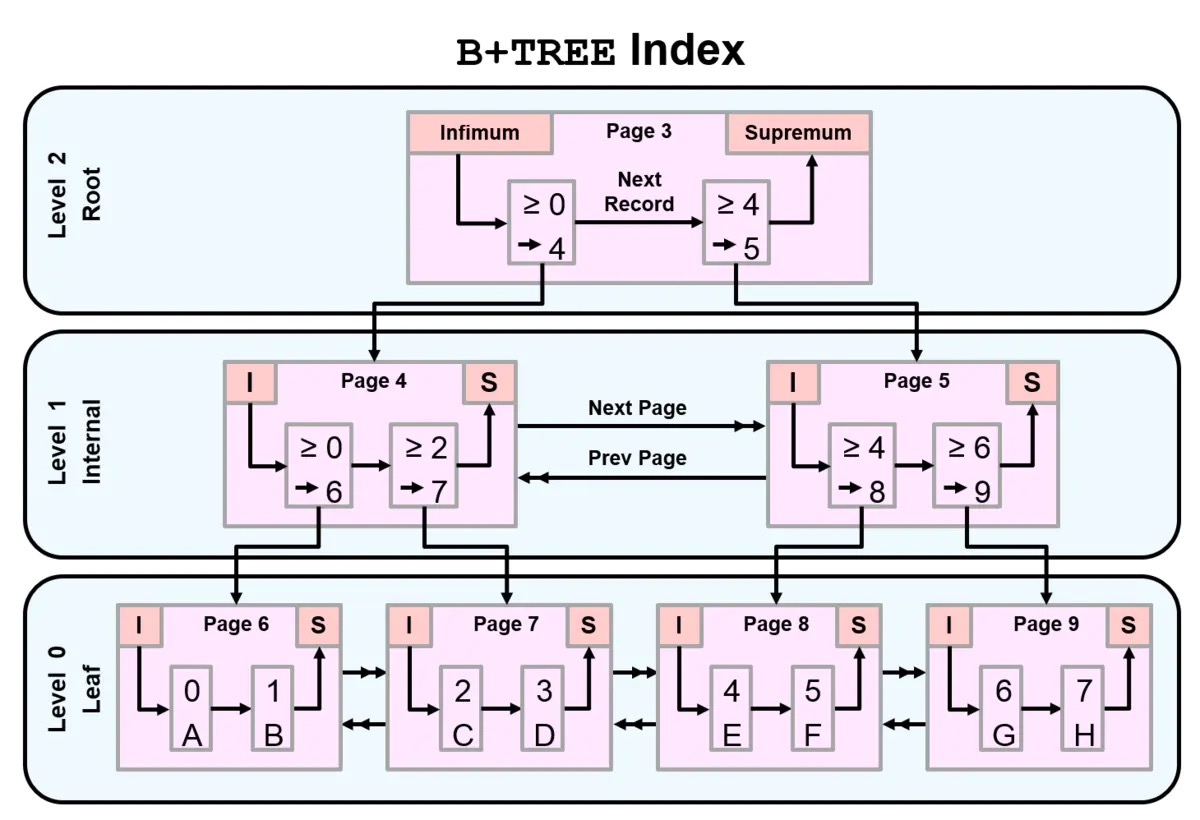
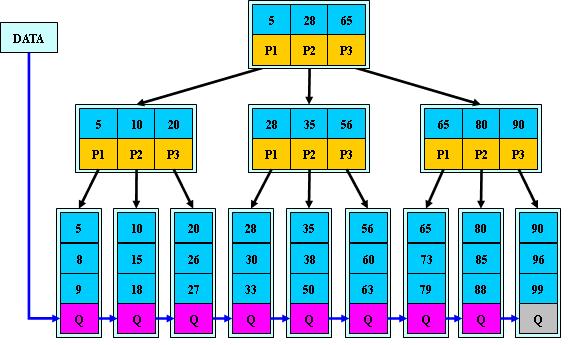
B-tree
B+Tree # 在范围查询方面提供了更好的性能(> < >= <= like) 页子节点有双向指针
B*Tree # 枝节点有双向指针
辅助索引和聚集索引
辅助索引(S)怎么构建 B 树结构
1. 辅助索引是基于表的列进行生成的
2. 取出索引列的所有值(取出所有键值)
3. 进行所有键值的排序
4. 将所有的键值按顺序落到BTree索引的叶子节点上(16K)
5. 然后生成此索引键值所对应得后端数据页的指针
6. 进而生成枝节点和根节点
7. 叶子节点除了存储键值之外,还存储了相邻叶子节点的指针,另外还会保存原表数据的指针
id name age gender
select * from t1 where id=10;
问题: 基于索引键做where查询,对于id列是顺序IO,但是对于其他列的查询,可能是随机IO.
聚集索引(C)怎么构建 B 树结构
1. 建表时有主键列
2. 表中进行数据存储时,会按照ID列的顺序,有序的存储一行一行的数据到数据页上(聚集索引组织表)
3. 表中的数据页被作为聚集索引的叶子节点
4. 把叶子节点的主键值生成上层枝节点和根节点
聚集索引和辅助索引构成区别总结
1. 聚集索引只能有一个,非空唯一,一般是主键
2. 辅助索引可以有多个,是配合聚集索引使用
3. 聚集索引叶子节点,就是磁盘的数据行存储的数据页
4. MySQL是根据聚集索引,组织存储数据,数据存储时就是安装聚集索引的顺序进行存储数据
5. 辅助索引只会提取索引键值,进行自动排序生成B树结构
辅助索引细分
单列的辅助索引
联合多列辅助索引(覆盖索引)
唯一索引
影响索引树高度
数据行多 # 使用分表
索引列字符长度 # 前缀索引
数据类型 char varchar # 优化表设计
enum 优化索引高度 # 尽量使用
压测
产生数据
# 方式一 使用sql语句产生数据
create database d100w charset utf8mb4 collate utf8mb4_bin;
use d100w;
create table t100w (id int,num int,
k1 char(2),
k2 char(4),
dt timestamp) charset utf8mb4 collate utf8mb4_bin;
delimiter //
create procedure rand_data(in num int)
begin
declare str char(62) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
declare str2 char(2);
declare str4 char(4);
declare i int default 0;
while i<num do
set str2=concat(substring(str,1+floor(rand()*61),1),substring(str,1+floor(rand()*61),1));
set str4=concat(substring(str,1+floor(rand()*61),2),substring(str,1+floor(rand()*61),2));
set i=i+1;
insert into t100w values (i,floor(rand()*num),str2,str4,now());
end while;
end;
//
delimiter ;
# 插入100w条数据:
call rand_data(1000000);
commit;
# 方式二 直接导入测试表(可以会出现链接失效的情况)
cd /tmp
wget https://klcc-img-1251900471.cos.ap-chengdu.myqcloud.com/sql/100w.sql.zip
unzip 100w.sql.zip
mysql -uroot -p
create database test charset utf8mb4 collate utf8mb4_bin;
use test;
source /tmp/100w.sql
压力测试语句
# 没有创建索引之前
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k2='BC56'" engine=innodb \
--number-of-queries=2000 -uroot -p1 -verbose
# 4c8g 运行了400多秒
# 创建索引之后
# sql语句
alter table t100w add index idx_k2(k2);
# 命令行
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='test' \
--query="select * from test.t100w where k2='BC56'" engine=innodb \
--number-of-queries=2000 -uroot -p1 -verbose
# 4c8g 此时只需要1秒不到
索引管理
表结构说明
desc world.city;
+-------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| CountryCode | char(3) | NO | MUL | | |
| District | char(20) | NO | | | |
| Population | int(11) | NO | | 0 | |
+-------------+----------+------+-----+---------+----------------+
Field :列名字
key :有没有索引,索引类型
PRI: 主键索引
UNI: 唯一索引
MUL: 辅助索引(单列,联和,前缀)
索引的创建
辅助索引
# 创建索引的时候会短暂的锁表,业务不忙的时候操作
alter table t100w add index idx_k2(k2);
# 查看索引情况
use test;
desc t100w;
# 此时 k2 这一行中的 Key 值为 MUL, 为辅助索引
show index from t100w\G
唯一索引
# 建立唯一索的列不能有重复值
# 查看k1列不重复情况,如果有重复值就不能创建唯一索引
select count(distinct k1) from t100w;
select k1,count(k1) from t100w group by k1 having count(k1) >1;
# 当有重复值的时候创建唯一索引时会报错
alter table t100w add unique index idx_k1(k1);
前缀索引
# 只能用于字符串类型的列上
desc world.city;
alter table world.city add index indx_name(name(5)); # 用name列的前5个字符
desc world.city;
联合索引
alter table world.city add index idx_co_po(countrycode,population);
查看删除索引
# 查看索引
show index from world.city;
# 删除索引
alter table world.city drop index idx_co_po;
索引应用规范
建立索引的原则(DBA 运维规范)
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。那么索引设计原则又是怎样的 建表时一定要有主键,一般是个无关列
选择唯一索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。 例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。 如果使用姓名的话,可能存在同名现象,从而降低查询速度。 优化方案: (1) 如果非得使用重复值较多的列作为查询条件(例如:男女),可以将表逻辑拆分 (2) 可以将此列和其他的查询类,做联和索引 select count(*) from world.city; select count(distinct countrycode) from world.city; select count(distinct countrycode,population ) from world.city;经常作为 where 条件列,
order by、group by、join on、distinct的条件列值长度较长的索引,建议使用前缀索引
降低索引条目,一方面不要创建没用索引,不常使用的索引清理,
percon-toolkit有工具可以分析索引是否有用大表建索引时,要在业务不繁忙期间操作
尽量少在经常更新值的列上建索引
不走索引的情况(开发规范)
- 没有查询条件,或者查询条件没有建立索引
- 查询结果集是原表中的大部分数据,应该是 25%以上
- 索引本身失效,统计数据不真实
- 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括
(+,-,*,/,!) - 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误
<>,not in不走索引(辅助索引)like "%_"百分号在最前面不走
执行计划
作用
1. 上线新的查询语句之前,进行提前预估语句的性能
2. 在出现性能问题时,找到合理的解决思路
执行计划获取
# 一般是针对 select 语句获取执行计划
# 查看语句的执行计划
desc select * from test.t100w where k2='BC56';
explain select * from test.t100w where k2='BC56'\G
# 结果
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t100w
partitions: NULL
type: ref
possible_keys: idx_k2
key: idx_k2
key_len: 17
ref: const
rows: 406
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
# 参数说明
table: t100w # 表名,多表查询的时候关注
type: ref # 索引的应用级别
possible_keys: idx_k2 # 可能会使用到的索引
key: idx_k2 # 实际上使用的索引
key_len: 17 # 联合索引覆盖长度
rows: 406 # 查询的行数(越少越好)
Extra: NULL # 额外的信息
应用级别type详解
# type的级别如下,从上到下性能越好,至少优化到range以上
1. ALL: 全表扫描,不走索引
desc select * from t100w; # 没有条件能走索引的
没建立索引
建立索引不走
desc select * from t100w where k1='aa'; # 上面例子中创建的索引时针对k2列的,k1列并没有创建索引
desc select * from t100w where k2!='aaaa'; # 不等于的条件也是不走索引的
desc select * from t100w where k2 like '%xt%'; # 模糊查询时当%在前面时不走索引 或者not in也不走索引
2. index: 全索引扫描,将整个索引树全部扫描一遍才能达到效果
desc select k2 from t100w;
3. range: 索引范围扫描,扫描索引树的一部分
辅助索引 > < >= <= like in or # 这些语句会走范围扫描,尽量避免 in or
主键 !=
desc select * from world.city where id > 1000;
desc select * from world.city where id != 1000;
desc select * from world.city where countrycode like 'C%';
desc select * from world.city where countrycode in ('CHN','USA'); # 可以改写为下面的语句
desc
select * from world.city where countrycode='CHN'
union all
select * from world.city where countrycode='USA';
# 此时可以看到type级别为ref
4. ref: 辅助索引等值查询
desc select * from world.city where countrycode='CHN';
5. eq_ref: 在多表连接查询时 on 的条件列时唯一索引或主键
desc
select a.name,b.name,b.surfacearea
from world.city as a
join world.country as b
on a.countrycode=b.code
where a.population < 100;
6. const,system: 主键或唯一键等值查询
desc select * from world.city where id=10;
7. null: 查不到数据的时候
Extra额外的信息
```mysql
# 当出现 using filesort 时说明索引设计不合理, 使用了文件排序
desc select * from world.city where countrycode='CHN' order by population;
# 没见索引之前
desc select * from world.city where countrycode='CHN' order by population limit 10;
# 建立联合索引
alter table world.city add index idx_co_po(countrycode,population);
desc select * from world.city where countrycode='CHN' order by population limit 10;
结论:
1.当我们看到执行计划extra位置出现filesort,说明由文件排序出现
2.观察需要排序(ORDER BY,GROUP BY ,DISTINCT )的条件,有没有索引
3. 根据子句的执行顺序,去创建联合索引
```
面试题
```mysql
explain(desc)使用场景
题目意思: 我们公司业务慢,请你从数据库的角度分析原因
1.mysql出现性能问题,我总结有两种情况:
(1)应急性的慢:突然夯住
应急情况:数据库hang(卡了,资源耗尽)
处理过程:
1.show processlist; 获取到导致数据库hang的语句
2. explain 分析SQL的执行计划,有没有走索引,索引的类型情况
3. 建索引,改语句
(2)一段时间慢(持续性的):
(1)记录慢日志slowlog,分析slowlog
(2)explain 分析SQL的执行计划,有没有走索引,索引的类型情况
(3)建索引,改语句
```